 OOPSLA'98
Business Object Workshop IV
OOPSLA'98
Business Object Workshop IV
Adaptive Framework for the REA Accounting Model
Hiroaki Nakamura and Ralph E. Johnson
Department of Computer Science
University of Illinois at Urbana-Champaign
1304 W. Springfield Ave. Urbana, IL 61801 USA
E-Mail: hnakamur@cs.uiuc.edu, johnson@cs.uiuc.edu
ABSTRACT. Business applications must be able to adapt to a changing business environment, to access large amount of data and to be efficient. A framework for business applications must also be reusable and provide uniform access to information. We have developed a framework based on the REA accounting model that meets these requirements. It uses the active object-model and composite query technique for adaptability, the Interpreter pattern and the integrated query system for information uniformity, and incremental computation for performance. Each idea in our framework can be applied to many other business-object implementations.
KEY WORDS: Business Object, REA Model, Application Framework, Active Object-Model, Object Query Language, Incremental Computation
1. Introduction
1.1 REA Model
The REA model [McCarthy 82] is a technique for capturing information about economic phenomena. It describes a business as a set of economic resources, economic events and economic agents as well as relationships among them. Although the REA model was proposed as a result of the study of accounting theories, it can be applied to many other business domains. It can be used for inventory control by assigning goods to resources, transfers to events, and owners to agents. It can be used for payroll by assigning lengths of time to resources, time cards to events, and employees to agents. The REA model is a promising modeling technique for developing business applications because it has a solid foundation and it can be applied to nearly all business domains.
1.2 Conclusion Materialization Process
The REA model captures only essential aspects of economic phenomena; it does not include artifacts associated with journals or ledgers, such as debit, credit, receivables, or accounts. Instead, these elements are derived from REA-model objects. The process of deriving these elements from REA-model objects is called conclusion materialization. For example, the quantity on hand for an inventory item is obtained as the imbalance between the purchase events and the sale events for that inventory item. Owing to the clear separation of base objects from information derivation processes, (1) models are kept concise and easy to understand, (2) models can be used for many applications, and (3) derived artifacts are always consistent by means of the models.
1.3 Framework Approach
The REA model is a modeling technique distilled from accounting theories and is intended to be a foundation of information systems. It can reduce the gaps between business processes and the supporting software. We constructed an application framework for developing the systems based on the REA model. A framework is a representation of a reusable design by a set of classes and the way their instances interact. The framework approach is important for the following reasons:
1) A framework can give software infrastructure for the conclusion materialization processes as well as the REA model. Although a large number of studies have been made on the REA model, little attention has so far been given to the conclusion materialization processes. Since the REA model without conclusion materialization is a pure conceptual modeling technique, it was not clear how to implement systems using the REA model. The framework gives a standard way of representing the REA model plus the conclusion materialization as software.
2) A framework can make it easy to build high quality systems. Most existing systems based on the REA model heavily depend on relational database technology, but they tend to be inefficient. On the other hand, alternative implementations would require deep understanding of a variety of implementation techniques. If we can encapsulate the implementation details in an application framework, it would increase the quality and productivity of systems. Since the framework solves the implementation issues, its users can build quality systems on top of the framework easily.
1.4 Framework Design Issues
Building a framework is not easy. We have to address the following issues to construct a framework for supporting the REA Model.
Adaptability: One of the most important properties of a business application framework is adaptability. In order to stay competitive, every business is always changing. Thus, it is no longer sufficient to provide a business with a fixed information system. "Information systems, like the business systems they support, must be adaptive in nature" [Taylor 95]. The framework that is a basis of such systems must be highly adaptive so that it can promote adaptive software development. The difficulty is to decide what should be made changeable and how. A framework represents fixed portions of applications by definition.
Uniformity: Uniformity is another property to be pursued. It reduces the complexity of the framework. One typical application of the framework is to give a virtual view to the object model. One way of implementing the view is to generate it when needed; another is to update it every time the object model is changed. The two implementations are completely different, but they can be specified in the same way, as a declarative relationship between the model and the view, for example. Moreover, we often want to treat derived information and base information the same. The framework has to hide the diversity of implementation and to provide uniform access to information.
Performance: Another concern in designing a framework is performance. One of the fundamental ideas behind the REA Model is to keep fine-grained, atomic information, which allows us to build flexible systems. On the other hand, a straightforward implementation would impose a heavy penalty for the gaps between the information maintained by the systems and that required by end users. The challenge is to make the framework efficient while preserving the simplicity of the REA Model.
Our solutions to the issues described above are shown in Table 1. REA
object models are represented using the Active Object-Model pattern [Foote
& Yoder 98]. Conclusion materialization processes are specified by
queries in Object Query Language [Cattell & Barry 97] and implemented
with a combination of techniques, including query composition, the Interpreter
pattern [Gamma et al. 95] and incremental computation. Object models and
queries are integrated so that the framework is accessed in a uniform way.
These techniques will be discussed in the following sections.
|
|
|
|
| Adaptability | 2. Active Object-Model | 3. Composite Queries |
| Uniformity | 6. Model/Query Integration | 4. Interpreter Pattern |
| Performance |
|
5. Incremental Computation |
Table1: Framework Design Issues and Solutions
2. Active Object-Model
When building an REA object model, we have to identify economic entities, which are resources, events, or agents. A natural object-oriented way of representing the entities is to give classes such as Customer and Order, and create individual customers and orders as instances of the classes. However, this scheme is not flexible. Although an arbitrary number of instances can be created while a system is working, classes must be fixed before the system is deployed. The resulting system cannot respond to changing business requirements. Thus, in order to make more adaptive systems, we need an alternative object model that can be configured dynamically. Such an object model is called the Active Object-Model [Foote & Yoder 98].
A first step towards an active object-model is to incorporate the Type Object pattern [Johnson & Woolf 97], which allows new types to be created dynamically. This pattern uses two concrete classes, one that represents objects and another that represents their types (Figure 1 (a)). The Object class delegates common responsibilities to the Type class. Figure 1 (b) shows possible instances of the two classes. Employee is an instance of the Type class and two employees are instances of the Object class.
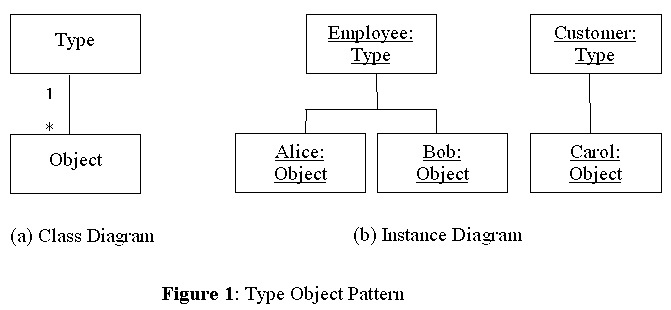
One significant responsibility of the Type class is to create instances of the Object class. The Type class acts as a builder of the Builder pattern [Gamma et al. 95], where instances of the Object classes are products of the builder. Figure 2 shows the elaborated object model of our framework. The Type class maintains attribute specifications and association specifications for the objects to be created. The attribute specifications designate the names and the types of the attributes. The association specifications designate the names and multiplicities (cardinalities) of the associations.
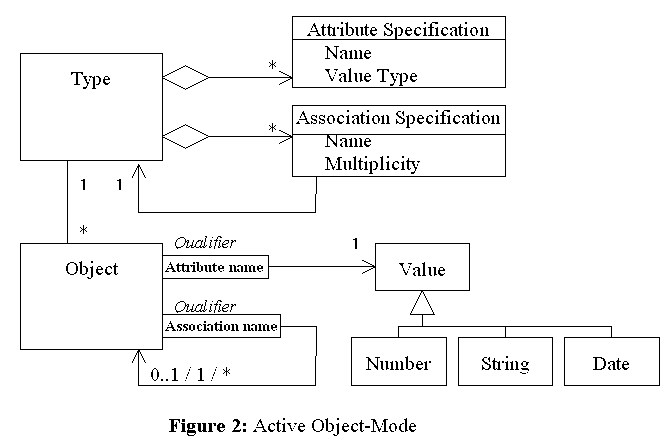
Instances of Object class are created according to the specifications stored in the Type objects. Attributes and associations are qualified by their names. The qualified attributes and associations are implemented using associative arrays, which are Dictionaries in Smalltalk. Such implementation of instance-variable equivalents is called Variable State pattern [Beck 96], in which the number and the kind of states vary from object to object. Attributes are value objects; associations are references to other objects. The major difference between them is that identity is important for referenced objects but not so important for value objects.
3. Composite Queries
We need to be able to describe the products of conclusion materialization. We selected the Object Query Language (OQL) [Cattell & Barry 97] as a specification language for conclusion materialization. OQL is a result of the attempt to standardize object-oriented query languages by the Object Database Management Group (ODMG). Its basic idea is to combine the declarative query description of SQL with the object-oriented paradigm. We first designed a special language for our framework, but we found OQL is much better because it is standardized and easy to use for those who know SQL. The following OQL query returns the set of the names of the employees whose ages are under 30:
Query 1:ODMG also defined the C++/Smalltalk/Java bindings for OQL. A query is executed by a member function (method) of the Collection class or by an object of the Query class. In either case, the query is specified by a character string with parameters. If all the queries can be defined in advance, this approach provides a solution that is easy to understand. However, if business requirements change at runtime, the character strings that represent queries also have to be modified. The problem is the strings have no structures connected with the requirements. End users or other parts of the system must be responsible for the consistency. What we need is a more flexible mechanism that can directly respond to the change in requirements.
SELECT e.name
FROM Employees e
WHERE e.age < 30
Unlike SQL, OQL is a functional language where operators can be composed freely. The result of a query expression can serve as an operand in the containing expression. This implies that any manipulation on the parse tree that represents a query is legal as long as operand types are correct. If nodes of the tree are instances of some classes, we can modify the tree without writing any classes or methods; what we need is only to create new instances and add them to the existing tree. Therefore, an OQL query represented by a parse tree is highly adaptive to the change in requirements.
We use slightly detailed abstract-syntax-trees instead of parse trees (concrete-syntax-trees) because some expressions are too complicated to represent as single nodes. For example, a select-from-where expression is composed of multiple kinds of nodes, though details are beyond the scope of this paper. Figure 3 shows the structure that represents the Query 1. All the sub-trees including the terminal nodes are queries, which structure is an application of the Composite pattern [Gamma et al. 95].
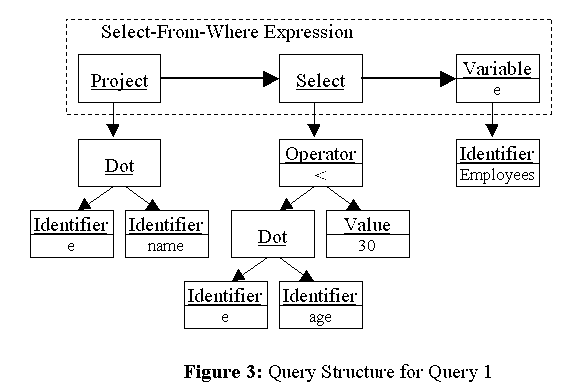
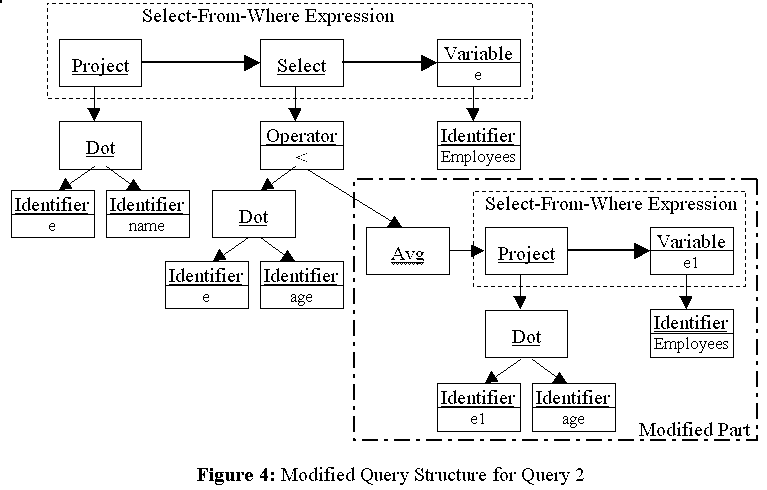
Suppose we need the names of employees whose ages are under the average, instead of 30. The query is written in OQL as:
We can get the new query structure by replacing the node that represents the value 30 with the tree that gives the average age. The result is shown in Figure 4. The point is that the structure can be configured dynamically while the system is running.Query 2:
SELECT e.name
FROM Employees e
WHERE e.age < AVG(SELECT e1.age FROM Employees e1)
4. Interpreter Pattern
The Interpreter pattern [Gamma et al. 95] describes how to represent sentences in a language and interpret these sentences. The pattern is intended for small languages because syntax trees and the operations attached to the nodes would become unmanageable for complex grammars. However, although OQL is quite a large language, we can easily apply the Interpreter pattern to it because it is a pure functional language, in which the value of a node is determined only by the values of its sub-trees.
One of the benefits of the Interpreter patterns is that adding new ways to interpret expressions is possible. A straightforward way is to see an OQL query as a procedure that starts evaluating the expression when invoked and returns a calculated value when finished. However, another interpretation is possible. We can also see an OQL query as a constraint between the input and the output. In this view, every time the input changes, it will notify the output. The output behaves as an observer of the input. The important point is that the same representation can be used for both interpretations. Query structures are exposed to users, but implementation details are hidden from them. The former way of interpretation is described in this section; the latter will be discussed in the next section.
Each query class has the operation evaluate: that takes a context as an argument and returns the value of the query. A context is any object that can respond to the message at:. A Dictionary object is one example and an instance of the Object class in the active object-model is another. There are two kinds of terminal queries: Identifier and Value. The Identifier query returns the result of sending at: to the context. The Value query returns the constant value that it contains. Non-terminal queries calculate their values using the results of the component queries.
Figure 5 shows how the sub-query 'e.age' is evaluated:
(1) The Dot query takes {e:{name:'Alice', age:25}} as the context.
(2) The Dot sends evaluate: {e:{name:'Alice', age:25}} to the left child.
(3) The left Identifier sends at: #e to {e:{name:'Alice', age:25}} and returns {name:'Alice', age:25}.
(4) The Dot sends evaluate: {name:'Alice', age:25}.to the right child.
(5) The right Identifier sends at: #age to {name:'Alice', age:25} and returns 25.
(6) The Dot returns 25 as the result.
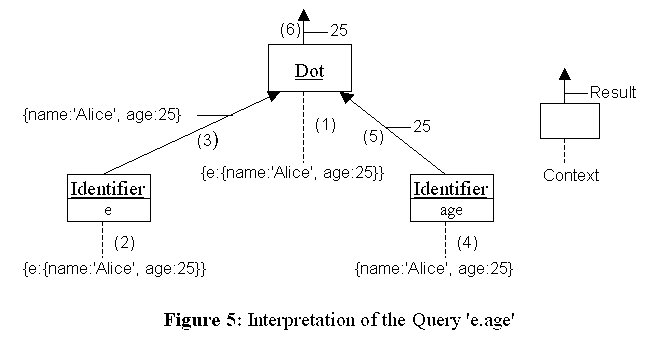
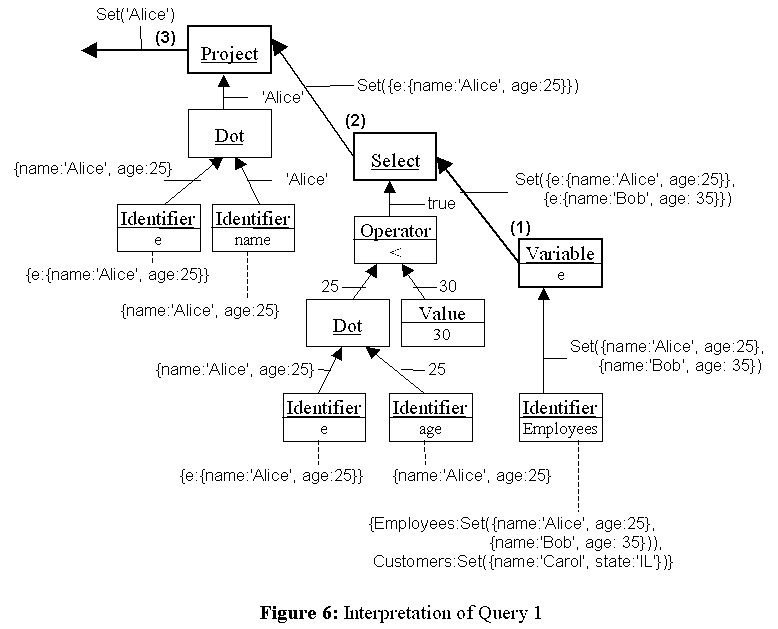
Figure 6 illustrates the interpretation process of Query 1. (1) The Variable query extracts employees and gives each employee the label e. (2) The Select query extracts the employees that satisfy the condition 'e.age<30'. (3) The Project query applies the query 'e.name' to each employee. The result is the set whose elements are the names of employees whose ages are under 30
5. Incremental Computation
One of the principles of the REA Accounting Model is that information about economic phenomena should be kept in as elementary a form as possible. As a result, the information can be used for many purposes. On the other hand, a conclusion materialization process, which transforms raw information into a summary that end users can understand, tends to be expensive because of the gap between the two forms of information.
In order to increase the performance of a conclusion materialization process, we introduced the incremental computation technique into our framework. In this technique, an output is computed using the result of the previous computation whose input was slightly different from the current one. In other words, the change in the input is used to update the output. This technique has been investigated in many fields, such as optimizing compilers and interactive systems. [Liu et. al] explored the transformation process from non-incremental programs into incremental programs.
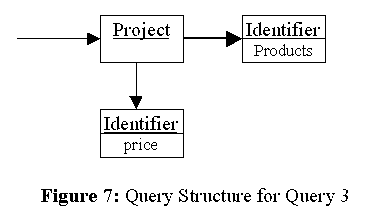
Let us show our algorithm using the following example query:
This query returns the set of the prices of products. The corresponding query structure is shown in Figure 7.Query 3:
SELECT price
FROM Products
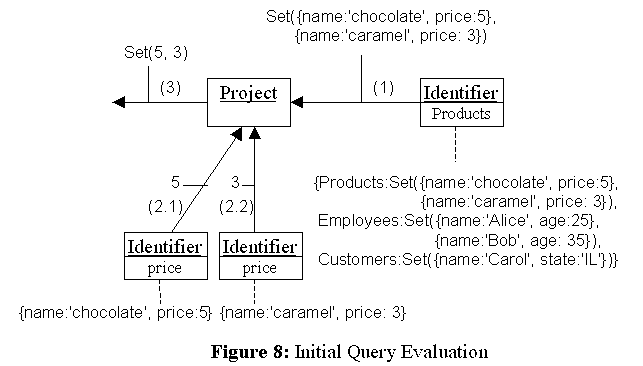
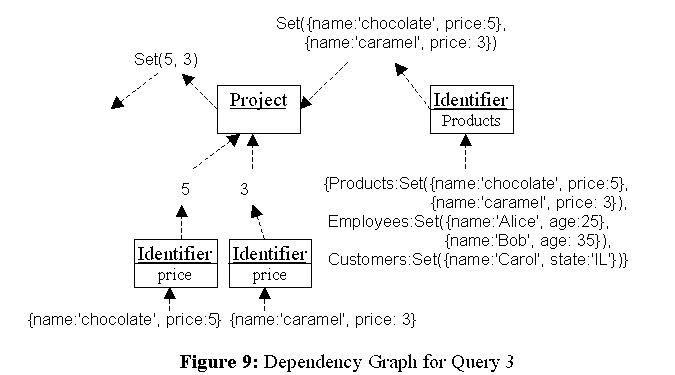
Our algorithm is composed of two phases. The first phase constructs the initial output from scratch. This phase is similar to the interpretation process discussed in the previous section. The difference is that the intermediate states, which are contexts and results of the sub-queries, are kept for future computations. To keep the intermediate states, we used the Prototype pattern [Gamma et al.]. Every time a query node is invoked, it creates a clone object and delegates the task to the clone. The clone is used as a holder of the intermediate states after the calculation. The Prototype pattern reduces the complexity of our framework because we need no extra classes. Figure 8 shows the initial evaluation process. Note that all the objects in Figure 8 are clones of the objects in Figure 7. (1) The left Identifier query extracts the set of products from its context. (2) The Project query invokes the bottom Identifier query twice because the set contains two elements. (2.1) The first bottom Identifier returns 5, and (2.2) the second bottom Identifier returns 3. (3) Finally, the Project query returns the set whose elements are 5 and 3.
The second phase computes the output using the dependency graph that
is constructed as a result of the first phase (Figure 9). Every node is
waiting for a change in its dependents. When a new product is added to
the system, that will be notified to the Project query through the left
Identifier query. The Project query generates a new Identifier query for
the newly added product and extracts the price from the product. Then,
the price is added to the set that is the output of the Project query.
The Observer pattern [Gamma et al.] is used to propagate the changes.
6. Model/Query Integration
So far, we have assumed that the queries are in the global scope. Our
framework also allows us to define local queries for specific classes,
which feature is not included in the ODMG OQL standard. Class-specific
queries act as methods of the classes and give us new views of the classes.
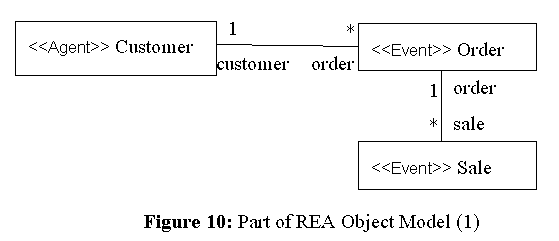
In the object model in Figure 10, Customer and Order are connected with each other and so are Order and Sale, but Customer and Sale are not. This design may be due to the decision on the conceptual model level. However, sometimes we find that it would be convenient if we had a link between Customer and Sale when we create a new application on top of the model. Queries attached to classes can be used to give such a new view. The following query defines a link from Customer to Sale:
This query can be accessed in the same way as the attributes and associations of the class Customer. If a Customer object is assigned to the variable c, c.order returns Order objects and c.sale returns Sale objects. The former is an access to an association and the latter is a query evaluation, but users see no difference. The query that gives a link from Sale to Customer can also be defined as:Query 4:
DEFINE sale AT Customer AS /* DEFINE [name] AT [class] AS [query] */
SELECT sale
FROM self.order order, order.sale sale
Query 5:
DEFINE customer AT Sale AS
self.order.customer
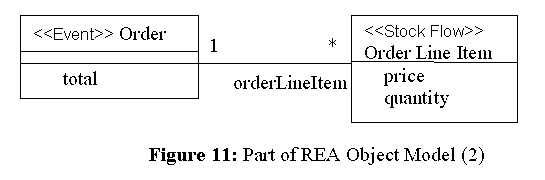
Here is another example. For the object mode in Figure 11, we can define a query of Order that calculates the total amount of line items as shown below:
If we take the incremental computation approach to evaluate the query, every time a line item is added to an order, the result of the query is updated automatically.Query 6:
DEFINE total AT Order AS
SUM(SELECT lineItem.price * lineItem.quantity FROM self.orderLineItem lineItem)
7. Concluding Remarks
We have shown how to construct an object-oriented framework that is suitable for REA-based applications. Central to the challenge in the framework design was how to achieve high adaptability, uniformity, and efficiency. We have finished the implementation of the framework except for the incremental computation mechanism. We are rewriting existing REA-based applications using our framework and examining how much of our goals have been attained. The problems we addressed are common to many other business-object systems, and we believe that the ideas described in this paper can be applied to other systems.
In addition, we plan to extend the system in several directions. The conclusion materialization processes in our framework do not change the base objects. This restriction is acceptable in many cases because our queries produce new views that can be handled in the same way as base objects. However, in some cases, it would be convenient if we had a mechanism to manipulate base objects in a controlled manner. One example is adding an adjusting event for depreciation, whose information is derived from existing base objects. Moreover, some accounting models including Fowler's [Fowler 97] heavily depend on posting internal events. Integrating event posting rules into the framework is one of the important topics to pursue.
Another direction is to support temporal concepts. Meaningful accounting information must be specified with either a point of time or duration of time. For example, a user may ask for a report on the last year's financial activities. In that case, we need the past states of the object model as well as the past rules to calculate taxes. When adding temporal information to the system, we have to consider how to keep track of the changes in objects, values, associations and queries. Then, we have to design a language to specify temporal information.
Our framework is so general that we can apply it to many types of applications. On the other hand, it does not directly support application specific concepts at the cost of generality. Instead, such high level concepts are described using the combination of object models and queries, which forms a language. By repeatedly building applications using the framework, we will be able to extract reusable fragments written in the language. One example is the combination of the object model in Figure 11 and the query in Query 6, which gives aggregated information of components. This pattern is also found in [Coad et al. 97] as the Transaction-Transaction Line Item Pattern. Activity Pattern [Geerts 97] formalized the patterns among events in the REA Model. Our framework has an ability to capture these patterns, and building application-specific frameworks on top of our current framework can be another research direction.
References
[Beck 96] K. Beck, Smalltalk Best Practice Patterns, Prentice Hall, 1996.
[Cattell & Barry 97] R.G.G. Cattell and D. K. Barry, The Object Database Standard: ODMG 2.0, Morgan Kaufmann Publishers, Inc., 1997.
[Coad et al. 97] P. Coad, D. North, M. Mayfield, Object Models Strategies, Patterns and Applications, Yourdon Press, 1997.
[Foote & Yoder 98] B. Foote and J. Yoder, "Metadata and Active Object-Models," 1998.
http://www-cat.ncsa.uiuc.edu/~yoder/papers/patterns/Metadata/metadata.pdf
[Fowler 97] M. Fowler, Analysis Patterns, Addison-Wesley, 1997.
[Gamma et al. 95] E. Gamma, R. Helm, R. Johnson, J. Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, 1995.
[Geerts 97] G.L.Geerts, "The Timeless Way of Building Accounting Information Systems: The Activity Pattern," OOPSLA'97 Business Object Workshop III, 1997.
[Johnson & Woolf 97] R. E. Johnson and B. Woolf, "Type Object," Pattern Languages of Program Design 3, Addison-Wesley, 1997.
[Liu et al. 96] Y. A. Liu, S. D. Stoller, T. Teitelbaum, "Discovering Auxiliary Information for Incremental Computation," Proceedings of POPL'96, ACM SIGPLAN, 1996.
[McCarthy 82] W. E. McCarthy, "The REA Accounting Model: A Generalized Framework for Accounting Systems in a Shared Data Environment," The Accounting Review, Vol. LVII, No. 3, 1982.
[Taylor 95] D. A. Taylor, Business Engineering with Object Technology,
John Wiley & Sons, Inc., 1995.
OOPSLA'98
Business Object Workshop IV